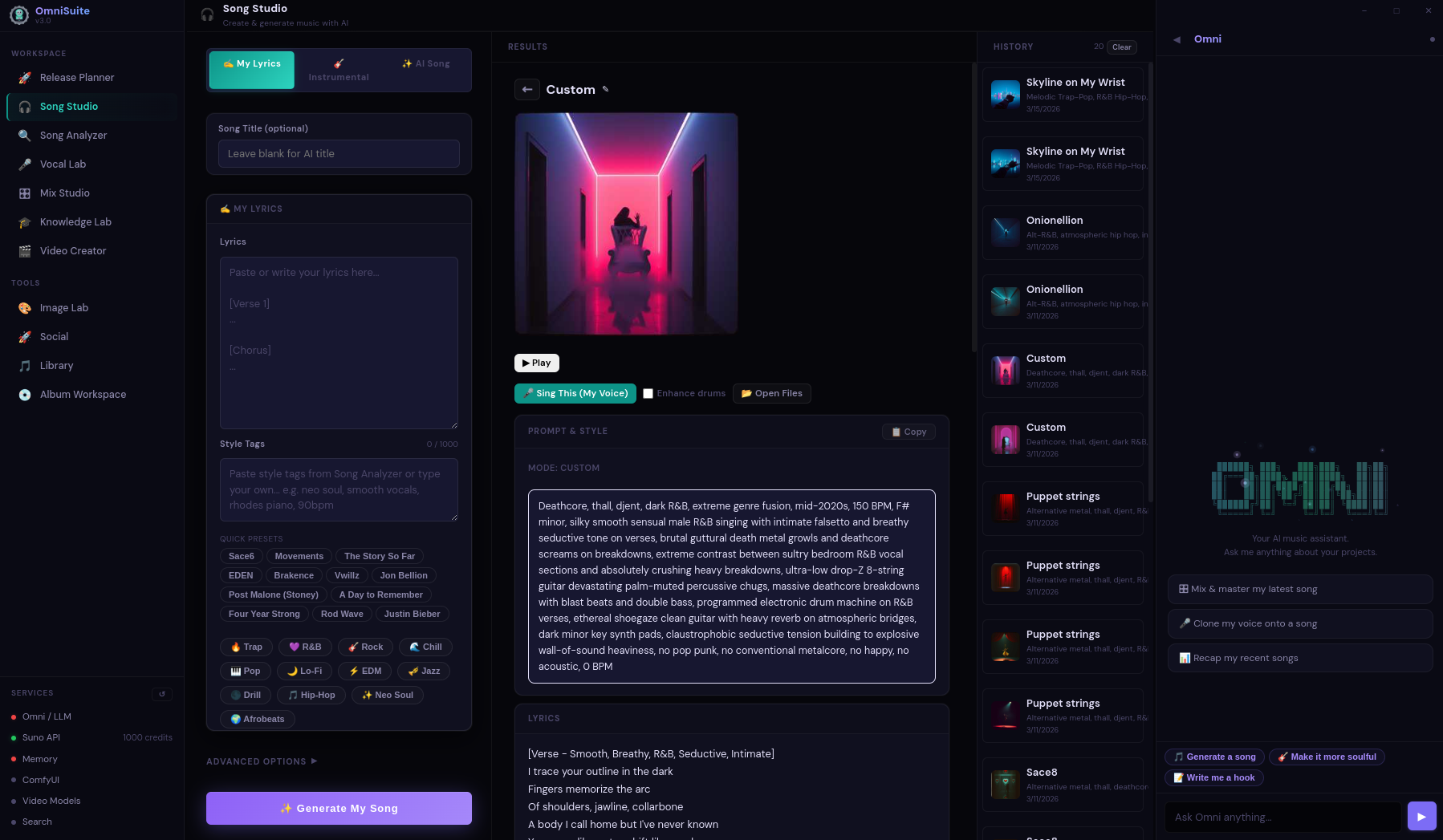
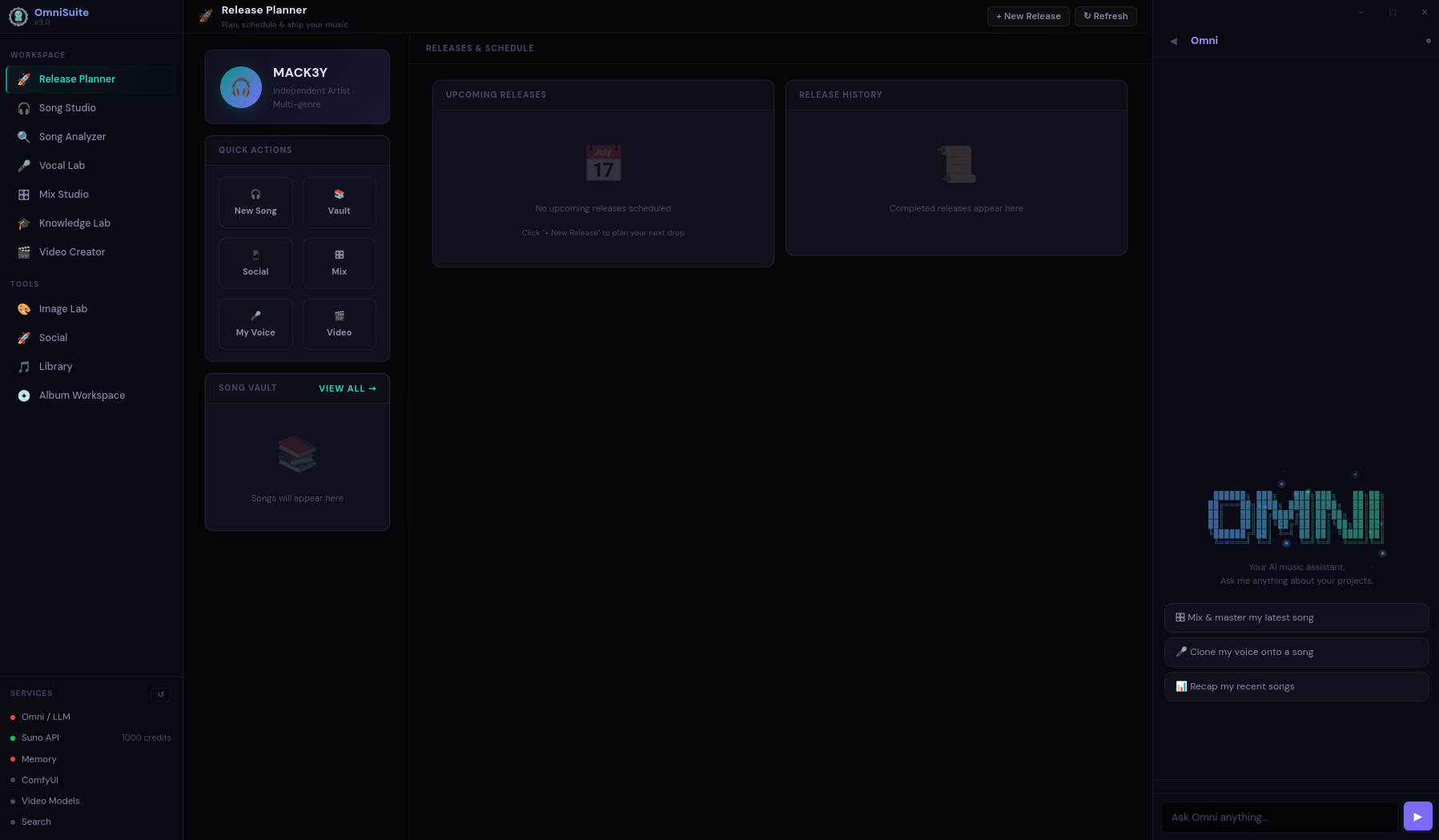
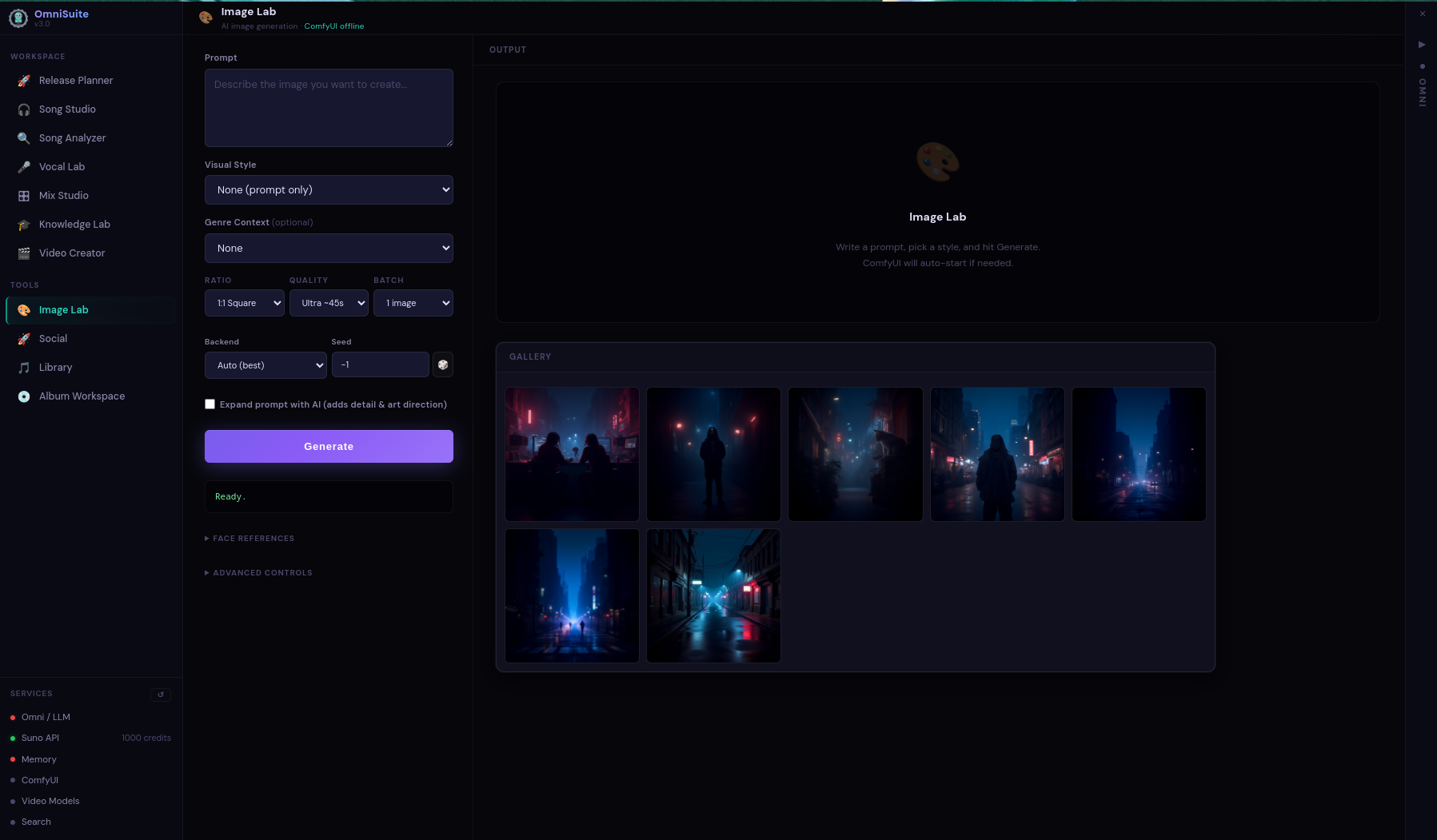
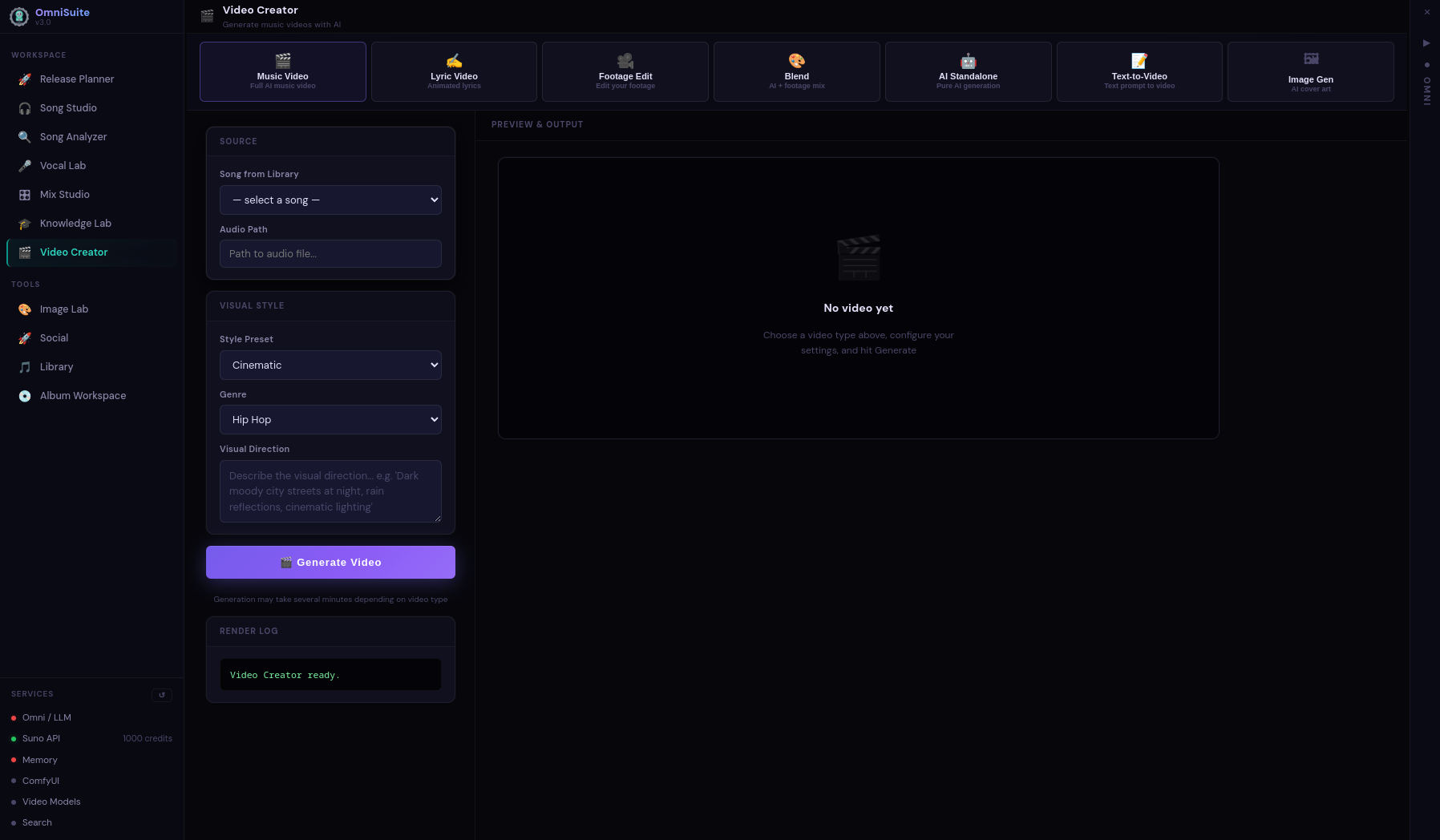
OmniSuite
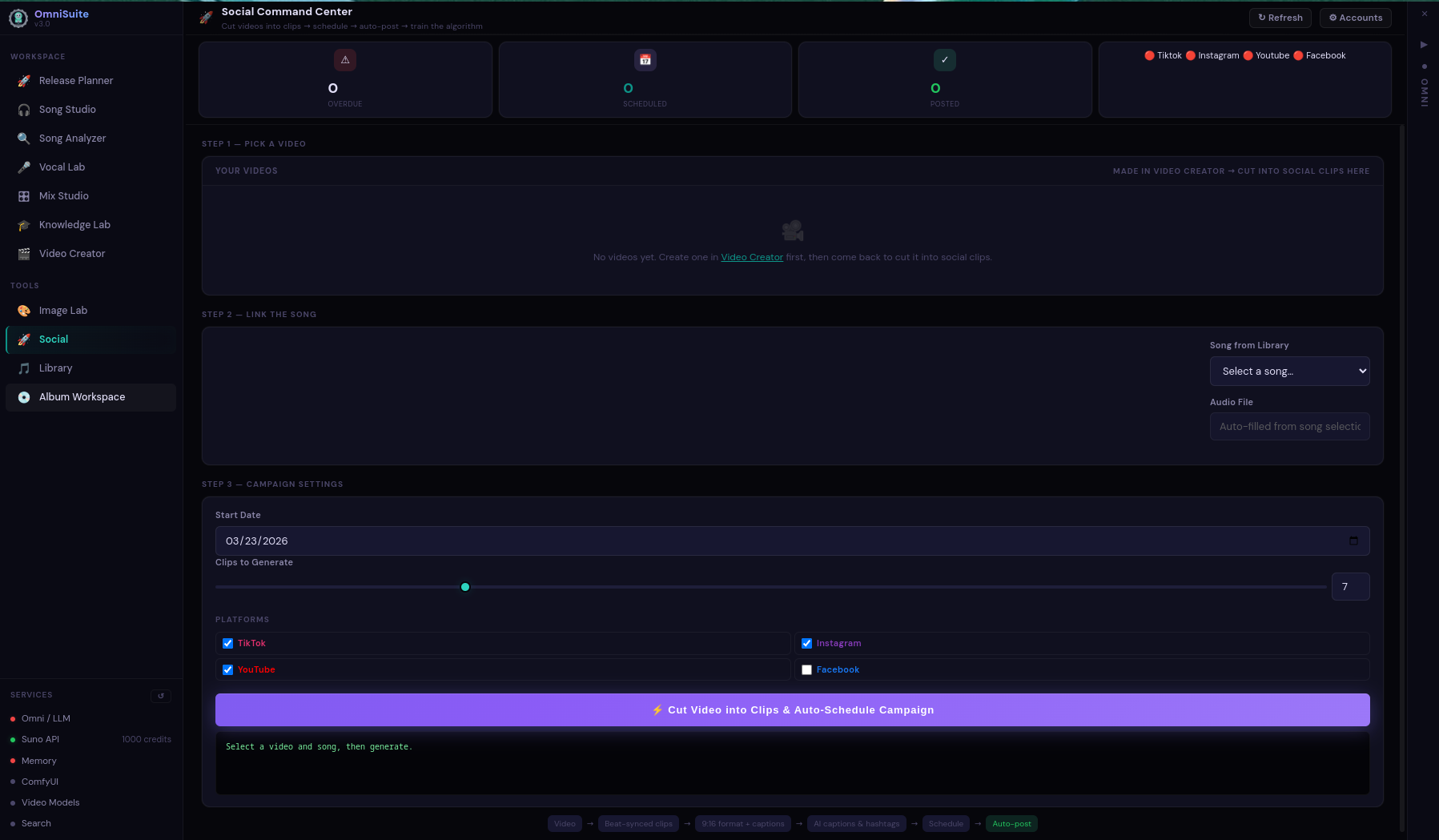
A full desktop platform for AI-assisted music production. Song generation, audio analysis, mixing, mastering, vocal production, image gen, video creation — all in one interface, all running locally.
Python / FastAPI
pywebview Desktop
RTX 5070 Ti
Local-First